

Se lavori con i CMS da abbastanza tempo, probabilmente hai già superato quella fase in cui ti entusiasmi perché “funziona tutto”, perché il sito è online, i contenuti si pubblicano senza intoppi e il cliente, almeno all’inizio, sembra soddisfatto del risultato ottenuto.
È una fase rassicurante, perché ti dà la sensazione di aver fatto la scelta giusta e di aver utilizzato strumenti collaudati, familiari, che non richiedono di mettere in discussione il modo in cui hai sempre lavorato.
Il problema è che questa tranquillità dura finché il progetto resta fermo.
Finché il frontend non deve evolvere. Finché i contenuti non devono vivere su più canali.
Finché nessuno ti chiede di integrare logiche più complesse, flussi diversi o architetture che vadano oltre il classico schema pagina–contenuto–tema.
Quando quel momento arriva, non esplode nulla.
Non c’è un errore evidente, non c’è un crash clamoroso, non c’è una scelta palesemente sbagliata da correggere.
C’è qualcosa di peggiore: inizi a renderti conto che ogni modifica richiede una spiegazione, una giustificazione, un compromesso che non avevi previsto all’inizio.
Ed è lì che, spesso senza dirlo apertamente, nasce una domanda che pesa più di tutte le altre: questa architettura riuscirei davvero a difenderla davanti a uno sviluppatore più senior di me?
Non stiamo parlando di “funziona” o “non funziona”.
Stiamo parlando di scelte spiegabili, argomentabili, sostenibili nel tempo, anche quando il progetto cresce e quando tu stesso, tra uno o due anni, dovrai rimetterci mano con uno sguardo molto più critico.
I CMS headless entrano in gioco esattamente in questo punto del percorso professionale.
Non come una moda da seguire perché se ne parla tanto.
Non come l’ennesimo strumento da aggiungere allo stack.
Ma come una conseguenza naturale di un cambio di mentalità, che ti porta a separare ciò che prima era confuso, accoppiato e mescolato per comodità.
Questo articolo non nasce per insegnarti come usare un CMS headless, né per convincerti che sia sempre la scelta giusta.
Serve piuttosto a chiarire cosa significa davvero headless, perché questo approccio nasce proprio dai limiti strutturali dei CMS tradizionali e, soprattutto, quale tipo di sviluppatore sei quando inizi a considerarlo seriamente.
Se stai cercando una soluzione rapida o una risposta rassicurante, probabilmente qui non la troverai.
Se invece senti che alcune decisioni architetturali non possono più essere prese “per abitudine”, allora sei esattamente nel punto giusto per iniziare il ragionamento.
Cos’è la modalità headless?
Quando si parla di modalità headless, spesso si parte da una definizione tecnica che sembra chiarire tutto, ma che in realtà lascia fuori proprio la parte più importante del discorso.
Dire che “il frontend è separato dal backend” è corretto, ma non spiega perché questa separazione diventa rilevante solo a un certo punto della vita di un progetto.
La modalità headless non nasce per semplificare il lavoro di chi sviluppa, né per rendere il CMS più moderno sulla carta.
Nasce quando il CMS, da strumento utile, inizia a occupare uno spazio che non dovrebbe più occupare, prendendo decisioni architetturali al posto tuo senza che tu te ne accorga subito.
In un sistema headless, il CMS smette di essere responsabile di come i contenuti vengono mostrati e si limita a fare una cosa precisa: conservarli, strutturarli e renderli disponibili in modo coerente.
Tutto ciò che riguarda presentazione, interazione e logica applicativa viene spostato altrove, dove può evolvere senza trascinarsi dietro vincoli che non hanno più senso.
Questo cambio non è neutro.
Ti costringe a chiederti chi decide cosa, dove passa il confine tra contenuto e applicazione e quali responsabilità stai assegnando a ogni parte del sistema.
La modalità headless diventa rilevante quando i contenuti smettono di essere semplici pagine e iniziano a essere risorse condivise, riutilizzabili, destinate a vivere su frontend diversi, magari scritti con tecnologie che il CMS tradizionale non aveva nemmeno previsto.
In quel momento, l’accoppiamento tra contenuto e interfaccia, che prima sembrava comodo, diventa un limite difficile da giustificare.
Scegliere un approccio headless significa accettare che alcune comodità iniziali vadano perse, in cambio di una maggiore chiarezza strutturale.
Non è una scelta che rende tutto più facile, ma è una scelta che rende il sistema spiegabile, soprattutto quando qualcuno con più esperienza inizia a farti domande sul perché certe decisioni sono state prese.
Ed è proprio lì che la modalità headless smette di essere un concetto astratto e diventa una risposta concreta a un problema che non riguarda il CMS, ma il modo in cui stai progettando il software.
Ma cosa vuol dire headless?

Il termine headless viene spesso usato come etichetta tecnica, ma se lo prendi alla lettera dice molto più di quanto sembri, soprattutto se lo guardi dal punto di vista di chi progetta sistemi e non di chi si limita a montarli.
Headless significa letteralmente “senza testa”, ma nel contesto di un CMS non indica l’assenza di qualcosa, bensì la scelta consapevole di togliere al sistema una responsabilità che prima esercitava in modo implicito.
Nei CMS tradizionali, la “testa” è l’interfaccia, ovvero il meccanismo attraverso cui il contenuto viene trasformato in pagine, layout, navigazione e comportamenti visivi.
Questa testa non è opzionale, perché è integrata nel cuore del sistema e finisce per condizionare ogni altra decisione, anche quando il progetto cresce e le esigenze cambiano.
Quando parliamo di headless significato, stiamo parlando di una scelta che rompe questo automatismo.
Il CMS continua a esistere, continua a gestire contenuti, modelli, relazioni e flussi editoriali, ma smette di imporre un modo predefinito di mostrarli.
La testa non sparisce, viene semplicemente spostata altrove, in un livello che puoi progettare, sostituire e far evolvere senza dover rinegoziare ogni volta il ruolo del CMS.
Questo spostamento ha un effetto immediato sul modo in cui ragioni.
Non puoi più affidarti a scorciatoie implicite, perché il collegamento tra contenuto e interfaccia non è più automatico.
Devi decidere come il frontend consuma i dati, quali API espone il CMS, quali trasformazioni avvengono e dove, e soprattutto chi è responsabile di cosa.
È qui che molti sviluppatori capiscono che headless non è sinonimo di “più moderno”, ma di “più esplicito”.
Ogni scelta diventa visibile, ogni accoppiamento deve essere giustificato e ogni compromesso emerge subito, invece di nascondersi dietro convenzioni comode che funzionano solo finché nessuno le mette in discussione.
Un CMS headless ti costringe a guardare il sistema come un insieme di parti che collaborano, non come un blocco unico che fa tutto.
Ed è proprio questa perdita di comfort iniziale che rende l’approccio interessante per chi ha già superato la fase in cui basta far funzionare le cose e inizia a chiedersi se ciò che sta costruendo è davvero difendibile nel tempo.
In altre parole, headless non descrive una tecnologia, ma un cambio di responsabilità.
E se questa distinzione ti sembra importante, è probabile che tu stia già ragionando a un livello in cui il CMS non è più il protagonista, ma solo uno degli attori dell’architettura.
Se leggendo questa sezione hai avuto la sensazione che il problema non fosse il CMS, ma le responsabilità che stavi delegando, probabilmente sei già oltre la fase dei tutorial.
Nel Corso Architetto Software AI lavoriamo proprio su questo passaggio: imparare a rendere esplicite le scelte, prima che diventino debito invisibile.
Puoi dare un’occhiata al percorso e capire, in pochi minuti, se è allineato al livello di decisioni che stai iniziando a prendere.
Cosa si intende per CMS?
Quando si parla di CMS, soprattutto dopo anni di utilizzo quotidiano, è facile dare il concetto per scontato e ridurlo a qualcosa di operativo, come se fosse semplicemente uno strumento per inserire contenuti, gestire pagine e far lavorare in autonomia chi non scrive codice.
In realtà, un CMS è sempre stato molto di più di questo, anche quando non ce ne rendevamo conto, perché fin dall’inizio ha incarnato una precisa idea di come contenuti, struttura e presentazione dovessero convivere all’interno dello stesso sistema.
Un CMS nasce come risposta a un’esigenza chiara: separare i contenuti dal codice applicativo, permettendo di aggiornarli senza dover intervenire ogni volta sullo sviluppo.
Il problema è che, nel tempo, questa separazione è diventata parziale, perché la maggior parte dei CMS tradizionali ha finito per inglobare non solo la gestione dei contenuti, ma anche la logica di rendering, il layout, la navigazione e spesso persino parti di comportamento applicativo.
Questo accentramento inizialmente è sembrato una virtù.
Avere tutto nello stesso posto rendeva il sistema più semplice da usare, più rapido da avviare e più accessibile anche a chi non aveva competenze tecniche profonde.
Ma ogni scelta che semplifica troppo all’inizio introduce un costo che emerge solo più tardi, quando il progetto smette di essere un sito e inizia a diventare un sistema.
Il punto critico non è il CMS in sé, ma il fatto che, così come viene comunemente inteso, il CMS decide implicitamente come il software deve essere costruito.
Decide come i contenuti diventano pagine.
Decide come il frontend deve interrogare i dati.
Decide quali compromessi sei disposto ad accettare in cambio di velocità iniziale.
Finché lavori su progetti semplici, questo patto non viene mai messo in discussione.
Ma quando il contesto cambia, quando il contenuto deve essere distribuito su più canali, quando il frontend diventa un’applicazione vera e propria o quando entrano in gioco requisiti che non erano previsti all’inizio, quel patto inizia a pesare.
Capire cosa si intende davvero per CMS significa quindi riconoscere che non stai scegliendo solo uno strumento editoriale, ma un modello architetturale implicito.
Ogni CMS porta con sé una visione su chi controlla il flusso dei dati, su dove avviene la trasformazione del contenuto e su quanto margine hai nel separare responsabilità diverse senza forzare il sistema.
È da questa consapevolezza che nasce il bisogno di ripensare il ruolo del CMS, non per eliminarlo, ma per rimetterlo al suo posto.
E quando inizi a farti queste domande, non stai più ragionando come qualcuno che deve “gestire contenuti”, ma come uno sviluppatore che vuole poter spiegare, senza esitazioni, perché il cuore del suo software è organizzato in un certo modo.
Perché i CMS tradizionali mostrano tutti i loro limiti
I limiti dei CMS tradizionali non emergono quando tutto fila liscio, ma quando il progetto inizia a fare esattamente ciò che dovrebbe fare un buon software: crescere, adattarsi e rispondere a esigenze che non erano completamente prevedibili all’inizio.
All’inizio, infatti, questi sistemi sembrano offrire tutto ciò che serve, perché ti permettono di partire in fretta, di avere subito qualcosa di visibile e di risolvere molti problemi con configurazioni, temi e plugin che sembrano fatti apposta per evitare decisioni difficili.
Il punto è che questa apparente completezza ha un prezzo che non viene pagato subito, ma accumulato nel tempo sotto forma di accoppiamenti invisibili.
Puoi rendere espliciti questi accoppiamenti invisibili chiarendo che, nella pratica quotidiana, un CMS tradizionale tende a legare tra loro elementi che dovrebbero restare indipendenti, come ad esempio:
- Il contenuto, che viene modellato in funzione di una singola struttura di pagina
- Il frontend, che deve sottostare alle regole di rendering imposte dal CMS
- Le estensioni, che risolvono problemi locali ma introducono dipendenze difficili da rimuovere
- La logica applicativa, che finisce per infiltrarsi dove dovrebbe esserci solo presentazione
E ogni estensione aggiunta per risolvere un problema locale introduce una dipendenza che rende il sistema meno leggibile e più difficile da spiegare.
Quando il progetto è piccolo, questi compromessi passano inosservati.
Ma quando inizi ad aggiungere funzionalità, a integrare servizi esterni o a supportare più canali di distribuzione, ti accorgi che il CMS tradizionale non sta più facilitando il lavoro, bensì lo sta guidando in una direzione che non hai scelto consapevolmente.
È in quel momento che le soluzioni diventano workaround e le scorciatoie iniziano a somigliare a pezze.
Il vero limite non è tecnico, ma concettuale.
Un CMS tradizionale assume che contenuto e presentazione debbano vivere insieme, perché nasce in un’epoca in cui il sito web era il canale principale, se non l’unico.
Oggi però i contenuti devono alimentare applicazioni, servizi, interfacce diverse, e quell’assunzione di base inizia a scricchiolare sotto il peso di requisiti che non può più sostenere senza forzature.
A questo punto, ogni nuova richiesta diventa una negoziazione con lo strumento.
Puoi farlo, ma devi piegare la struttura.
Puoi integrarlo, ma devi accettare compromessi.
Puoi evolverlo, ma devi spiegare perché l’architettura è diventata così complessa rispetto al problema che dovrebbe risolvere.
Ed è qui che entra in gioco la difendibilità tecnica.
Se devi giustificare ogni scelta come “l’unico modo possibile con questo CMS”, significa che non stai più progettando il sistema, ma lo stai subendo.
Riconoscere i limiti dei CMS tradizionali non vuol dire rifiutarli in blocco, ma capire quando il loro modello mentale non è più allineato con il tipo di software che stai cercando di costruire e con il livello di responsabilità che vuoi assumerti come sviluppatore.
Come funziona un CMS headless a livello architetturale
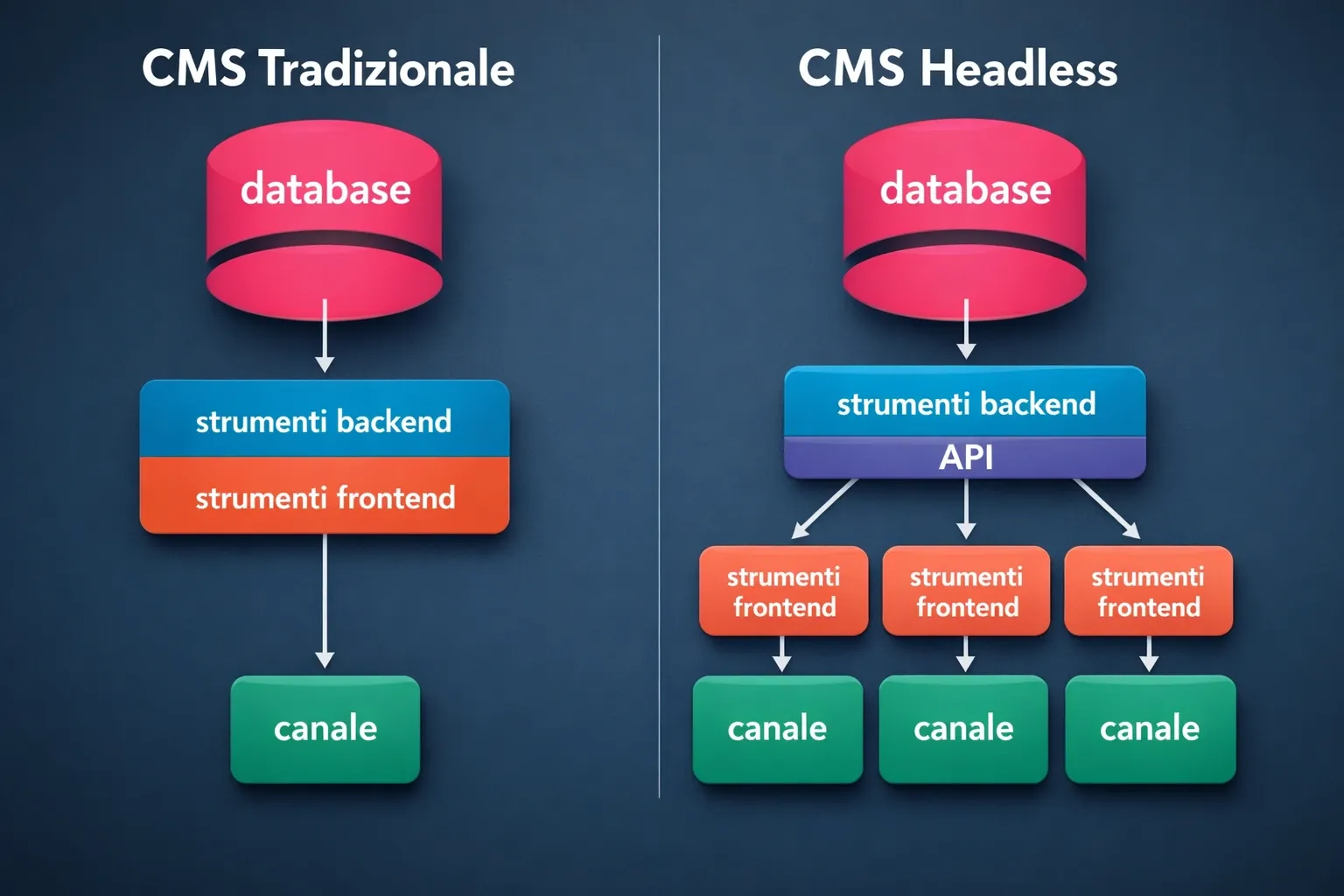
Quando inizi a guardare un CMS headless dal punto di vista architetturale, la prima cosa che cambia è che smetti di pensarlo come un blocco unico e inizi a vederlo per quello che è realmente: un componente specializzato all’interno di un sistema più ampio.
Questa distinzione sembra banale, ma è esattamente il punto in cui molti progetti iniziano a diventare difendibili, perché ogni parte torna ad avere un ruolo chiaro e limitato, invece di sovrapporsi alle altre per comodità.
In un’architettura headless, il CMS non ha alcuna responsabilità sulla presentazione finale dei contenuti.
Non decide come verranno mostrati, non conosce il layout, non sa nulla dell’esperienza utente.
Il suo compito è definire modelli di contenuto coerenti, gestire relazioni, versioni, workflow editoriali e rendere questi dati disponibili in modo affidabile tramite interfacce ben definite.
Tutto il resto avviene fuori.
Questo porta a una conseguenza importante: il CMS diventa un fornitore di dati, non un generatore di pagine.
Il frontend, che può essere un sito web, un’applicazione, un sistema esterno o più frontend contemporaneamente, consuma quei dati attraverso API e li trasforma in esperienza utente secondo logiche che non dipendono più dallo strumento editoriale.
In questo modo, il flusso dei dati è esplicito, tracciabile e soprattutto spiegabile.
Dal punto di vista di chi progetta, questo significa poter ragionare in termini di confini.
Sai dove nascono i contenuti.
Sai come vengono esposti.
Sai dove vengono interpretati.
Ogni passaggio è una scelta architetturale e non una conseguenza implicita del CMS che stai usando.
Questa chiarezza ha un costo iniziale, perché richiede di progettare prima di costruire, ma restituisce controllo nel momento in cui il sistema cresce.
Quando devi cambiare frontend, non tocchi il CMS.
Quando devi cambiare il modo in cui i contenuti vengono presentati, non riscrivi il backend.
E quando qualcuno ti chiede perché l’architettura è fatta in un certo modo, puoi rispondere senza rifugiarti in “è così perché il CMS funziona così”.
Un CMS headless funziona davvero a livello architetturale quando smette di essere percepito come il centro del sistema e diventa uno dei suoi servizi fondamentali.
È in quel momento che il software inizia a somigliare a qualcosa che può evolvere senza perdere coerenza e che può essere discusso, analizzato e difeso davanti a chiunque abbia sufficiente esperienza per guardarlo nel dettaglio.
API, contenuti e frontend: ruoli separati per scelta
La separazione tra API, contenuti e frontend viene spesso raccontata come una conseguenza tecnica dell’approccio headless, ma in realtà è una decisione intenzionale, che nasce dal momento in cui smetti di accettare che uno strumento scelga al posto tuo come deve funzionare l’intero sistema.
Qui non si tratta di distribuire componenti per moda o di seguire un pattern perché “si fa così”, ma di stabilire confini chiari che rendano l’architettura leggibile, governabile e soprattutto difendibile.
Quando il CMS espone i contenuti tramite API RESTful, sta dichiarando apertamente il suo ruolo.
Non interpreta, non presenta, non decide.
Rende disponibili dati strutturati, coerenti, versionati, e li consegna a chi li consumerà.
Questo passaggio è cruciale perché trasforma il contenuto in una risorsa, non in una pagina, e costringe chi sviluppa il frontend a trattarlo come tale, con tutte le responsabilità che ne derivano.
Il frontend, a sua volta, smette di essere un’estensione del CMS e diventa un’applicazione a tutti gli effetti.
Che sia un sito, una web app, un’app mobile o più interfacce contemporaneamente, il frontend prende decisioni autonome su come i contenuti vengono utilizzati, aggregati, trasformati e presentati.
Non chiede permesso al CMS, non ne subisce i limiti strutturali e può evolvere seguendo esigenze che cambiano senza trascinarsi dietro logiche che non gli appartengono.
Le API diventano il punto di contatto, ma anche il punto di responsabilità.
Definire un’API significa rendere esplicito un contratto, e un contratto, per sua natura, deve essere chiaro, stabile e giustificabile.
Nel momento in cui adotti questo approccio, stai implicitamente accettando alcune responsabilità architetturali che non possono più essere delegate allo strumento, tra cui:
- Decidere cosa è contenuto e cosa è logica
- Stabilire quali dati esporre e con quale granularità
- Mantenere stabile il contratto tra backend e frontend
- Rendere ogni scelta spiegabile a chi entrerà sul progetto dopo di te
Non puoi più nasconderti dietro chiamate interne o comportamenti impliciti, perché tutto ciò che passa da quell’interfaccia deve avere un senso architetturale preciso.
Stai rinunciando alla comodità di un sistema che fa tutto da solo in cambio della possibilità di spiegare, punto per punto, perché ogni componente esiste e quale problema risolve.
E quando qualcuno con esperienza guarda il sistema nel suo insieme, non vede un groviglio di dipendenze, ma una struttura in cui ogni parte ha un perimetro definito.
Separare API, contenuti e frontend non serve a complicare il software, ma a renderlo onesto.
A questo punto, la differenza tra un CMS tradizionale e un CMS headless non è più una questione di strumenti, ma di responsabilità che il sistema si assume o delega.
| Dimensione di confronto | CMS tradizionale | CMS headless |
|---|---|---|
| Ruolo del CMS | Sistema centrale che gestisce contenuti, presentazione e parte della logica | Servizio specializzato che gestisce contenuti e modelli |
| Rapporto contenuto e interfaccia | Accoppiato e spesso implicito, difficile da separare senza forzature | Separato e governato da un contratto esplicito |
| Responsabilità sulla presentazione | Interna al CMS tramite temi, template e regole di rendering | Esternalizzata al frontend, progettata e modificabile senza vincoli del CMS |
| Evoluzione del frontend | Condizionata dallo stack del CMS e dalle scelte del tema | Indipendente, sostituibile senza riscrivere il CMS |
| Esplicitazione delle scelte | Molte decisioni restano nascoste dietro convenzioni e scorciatoie | Ogni scelta è visibile, dichiarata e discutibile |
| Riutilizzo dei contenuti | Spesso limitato a un canale principale con adattamenti faticosi | Nativo su più frontend e canali, senza duplicare strutture |
| Gestione della complessità | Accumula dipendenze e workaround man mano che il progetto cresce | Distribuisce responsabilità tra componenti con ruoli chiari |
| Difendibilità architetturale | Spesso legata ai limiti dello strumento e alle sue regole interne | Legata alle decisioni prese e al perimetro assegnato a ogni parte |
| Posizionamento dello sviluppatore | Operatore dello strumento, orientato alla velocità di avvio | Progettista del sistema, orientato a confini e responsabilità |
Onesto nel modo in cui cresce.
Onesto nel modo in cui cambia.
Onesto nel modo in cui può essere discusso senza dover giustificare continuamente scelte che non hai mai fatto davvero.
A questo punto una domanda è inevitabile: sapresti spiegare questa architettura a un altro sviluppatore, senza appoggiarti a “funziona così”?
È esattamente su questo tipo di chiarezza che si costruisce il Corso Architetto Software AI: non pattern da copiare, ma criteri per decidere, difendere e far evolvere un sistema quando cresce.
Se vuoi capire come si allena davvero questo modo di ragionare, qui trovi il percorso completo.
Qual è il CMS più usato?
Quando si arriva a questa domanda, molti si aspettano ancora una risposta netta, un nome preciso da confrontare in termini di diffusione, quote di mercato o numero di installazioni.
È una reazione comprensibile, ma anche limitante, perché sposta l’attenzione sullo strumento invece che sulle decisioni che lo strumento ti costringe a prendere.
Chiedersi qual è il CMS più usato ha senso solo se prima chiarisci in quale contesto e per fare cosa, perché l’adozione non è mai un indicatore di qualità architetturale, ma solo di semplicità iniziale, familiarità o inerzia tecnica.
Nel mondo dei CMS tradizionali, alcune soluzioni dominano perché permettono di partire in fretta, offrono un ecosistema ampio e riducono il numero di scelte da fare all’inizio.
Questo spiega perché vengano utilizzate anche quando il progetto inizia a superare il perimetro per cui erano state pensate.
Il problema nasce quando la diffusione viene confusa con la solidità e si iniziano a giustificare architetture fragili con frasi come “lo usano tutti” o “è lo standard”.
In quel momento non stai più scegliendo consapevolmente, stai accettando compromessi per abitudine.
Nel mondo headless, però, la domanda cambia ancora.
Non stai più cercando il CMS più usato in assoluto, ma quello che interferisce meno con le scelte architetturali che contano davvero.
Uno strumento che faccia bene il suo lavoro senza cercare di governare tutto il resto.
È per questo che vengono citate soluzioni come Strapi: non perché siano definitive, ma perché rappresentano bene l’idea di CMS che accetta di essere un servizio, non il centro dell’architettura.
Espongono contenuti tramite API, permettono di modellare strutture complesse e si inseriscono in sistemi dove frontend e logica applicativa vivono altrove.
Ma quando la comprensione del problema cresce, anche questa distinzione inizia a non bastare più.
Arriva un momento in cui ti accorgi che nessun CMS in commercio può soddisfare davvero le tue esigenze, i tuoi flussi e le tue responsabilità senza introdurre compromessi inutili.
Non perché sia fatto male, ma perché è stato progettato per funzionare in molti contesti, non nel tuo.
È qui che prende forma un’altra possibilità, spesso trascurata: implementare il tuo CMS.
Implementare il proprio CMS, però, non significa per forza farlo da soli, né partire da zero sperando di non sbagliare.
Rischi di incappare in errori comuni, prevedibili, che quasi tutti commettono la prima volta.
Il vero vantaggio emerge quando questo percorso viene affrontato seguiti da chi quegli errori li ha già commessi, li ha risolti, e sa riconoscerli prima che diventino strutturali.
Errori di modellazione che sembrano innocui all’inizio. Scelte sulle API che funzionano oggi ma creano attrito domani.
Accoppiamenti che emergono solo quando il progetto cresce e tornare indietro costa molto più che decidere bene prima.
Essere seguiti significa risparmiare mesi di tentativi, perché non stai esplorando alla cieca, ma seguendo un percorso già tracciato, con le deviazioni pericolose ben note.
Ed è qui che il tempo diventa il vero costo.
È anche il punto in cui l’AI diventa davvero utile, se usata dentro un perimetro guidato, e non come scorciatoia senza controllo.
Oggi l’AI può accelerare enormemente lo sviluppo, ridurre le ore di scrittura e aiutare a esplorare soluzioni più velocemente, ma resta un acceleratore, non un sostituto del ragionamento.
Il codice generato va compreso, adattato, corretto e inserito in un disegno coerente, altrimenti l’effetto è solo quello di produrre più velocemente problemi più complessi.
Quando competenza ed esperienza si combinano con l’AI nel modo giusto, però, il risultato cambia: si accorciano i tempi, si evitano errori noti e si arriva prima a una soluzione funzionante e difendibile, senza passare da tentativi ciechi.
Alla fine, la domanda giusta non è quale CMS sia più usato, ma se il sistema che stai costruendo ti permette di spiegare, senza scuse, perché esiste ogni sua parte e perché non ne esistono altre.
Quando inizi a ragionare così, smetti di scegliere strumenti per popolarità e inizi a progettare sistemi per responsabilità.
Ed è in quel punto che il CMS headless smette di essere una moda, fino ad arrivare al momento in cui lo strumento non viene più scelto, ma costruito con criterio.
Quando è la scelta giusta?

Un CMS headless diventa la scelta giusta non quando hai bisogno di qualcosa di più moderno, ma quando inizi a sentire che le decisioni architetturali che stai prendendo oggi dovranno reggere domani, davanti a persone che non accetteranno risposte vaghe o giustificazioni basate sull’abitudine.
È una scelta che matura nel tempo, spesso dopo aver già sperimentato i limiti di un CMS tradizionale e aver capito che il problema non era lo strumento in sé, ma il modello implicito che ti costringeva a pensare in un certo modo.
In pratica, questo momento arriva quando inizi a riconoscere segnali precisi nel tuo modo di lavorare, come ad esempio:
- ti accorgi che ogni nuova richiesta richiede compromessi architetturali sempre più difficili da spiegare
- inizi a separare mentalmente contenuti, logica e presentazione, anche se lo strumento non lo prevede
- senti che alcune scelte “comode” oggi diventeranno un problema domani
- smetti di chiederti come farlo e inizi a chiederti se ha senso farlo così
La scelta di un CMS headless ha senso quando il contenuto smette di essere legato a una singola interfaccia e diventa una risorsa che deve alimentare più frontend, più canali o più esperienze, senza che ogni nuova esigenza comporti una ristrutturazione profonda del sistema.
In questi casi, continuare a usare un CMS che lega contenuto e presentazione significa accettare un accoppiamento che non è più difendibile, soprattutto quando il progetto cresce e le richieste diventano meno prevedibili.
È la scelta giusta quando il frontend non è più un semplice layer di rendering, ma un’applicazione con logiche proprie, ritmi di rilascio indipendenti e vincoli che non possono essere subordinati alle regole interne del CMS.
In questo scenario, forzare il frontend dentro i confini di uno strumento pensato per tutt’altro scopo genera frizione, rallenta le evoluzioni e rende ogni modifica più costosa di quanto dovrebbe essere.
Un CMS headless diventa sensato anche quando inizi a ragionare in termini di responsabilità separate, non perché qualcuno te lo ha suggerito, ma perché senti il bisogno di poter indicare con precisione dove nascono i contenuti, dove vengono trasformati e dove diventano esperienza utente.
Questa chiarezza non semplifica il lavoro nel breve periodo, ma lo rende più solido nel medio e lungo termine, soprattutto quando il sistema deve essere compreso, manutenuto o esteso da persone diverse da te.
Non è la scelta giusta, invece, se stai cercando una soluzione più veloce o un modo per evitare decisioni complesse.
Un CMS headless richiede di assumersi la responsabilità dell’architettura e di accettare che alcune comodità iniziali vadano perse in cambio di controllo e trasparenza.
Se questo scambio ti sembra eccessivo, probabilmente non è ancora il momento.
Ma quando inizi a pensare che un’architettura dovrebbe essere spiegabile senza scuse, che le scelte dovrebbero reggere una revisione critica e che il software dovrebbe poter crescere senza accumulare debito invisibile, allora un CMS headless smette di essere una possibilità astratta e diventa una risposta concreta a un’esigenza reale.
Come si sviluppa un CMS headless sostenibile
Sviluppare un CMS headless sostenibile non significa scegliere lo strumento giusto e sperare che faccia il resto, perché la sostenibilità, in questo contesto, non è una proprietà del CMS ma dell’insieme delle decisioni che prendi intorno ad esso.
Un CMS headless può essere tecnicamente corretto e allo stesso tempo diventare insostenibile se viene inserito in un’architettura che replica gli stessi errori concettuali dei CMS tradizionali, solo distribuiti su più componenti.
La sostenibilità nasce dal modo in cui definisci i modelli di contenuto, perché è lì che decidi quanto il sistema sarà flessibile o rigido nel tempo.
Modelli troppo generici sembrano adattarsi a tutto, ma finiscono per non rappresentare nulla in modo chiaro, mentre modelli troppo specifici legano il contenuto a casi d’uso contingenti che potrebbero non esistere più tra un anno.
Trovare il punto di equilibrio richiede di ragionare sul dominio, non sull’interfaccia, e questo è già un primo segnale di maturità progettuale.
Un altro aspetto centrale riguarda le API, che in un sistema headless diventano il vero contratto tra il CMS e il resto dell’architettura.
API sostenibili sono API pensate per essere stabili, leggibili e versionabili, non semplici scorciatoie per far funzionare il frontend di oggi.
Ogni endpoint racconta una scelta, e se quella scelta non è chiara nemmeno a chi l’ha fatta, difficilmente potrà essere difesa quando il sistema crescerà o cambierà direzione.
La sostenibilità passa anche dal modo in cui il CMS viene integrato nel flusso di sviluppo.
Un CMS headless non dovrebbe imporre ritmi, processi o dipendenze che rallentano il lavoro del team, ma inserirsi in una pipeline coerente, in cui contenuti, codice e deploy su infrastruttura cloud seguono logiche compatibili.
Quando questo allineamento manca, il CMS diventa un collo di bottiglia, anche se tecnicamente è stato scelto per evitarli.
Infine, c’è un aspetto spesso sottovalutato, che riguarda la comprensibilità del sistema nel tempo.
Un CMS headless sostenibile è quello che puoi spiegare a un altro sviluppatore senza dover raccontare la storia completa di ogni scelta fatta in passato.
Se l’architettura richiede troppe eccezioni, troppe note a margine o troppe “soluzioni temporanee”, significa che qualcosa non è stato progettato per durare.
Sviluppare un CMS headless sostenibile, in definitiva, significa accettare che la tecnologia è solo una parte del problema e che la vera differenza la fanno le decisioni che rendono il sistema leggibile, estendibile e difendibile anche quando chi l’ha costruito non è più l’unico a conoscerlo a fondo.
Il cambio di mentalità richiesto allo sviluppatore

Arrivare a considerare seriamente un CMS headless non è il risultato di aver scoperto una nuova tecnologia, ma la conseguenza di un cambiamento molto più profondo nel modo in cui guardi il tuo ruolo di sviluppatore.
È il passaggio da chi esegue soluzioni che funzionano a chi prende decisioni che devono reggere nel tempo, anche quando il contesto cambia e le persone coinvolte nel progetto non sono più le stesse.
Il cambio di mentalità inizia quando smetti di valutare una scelta solo in base a quanto è comoda oggi e inizi a chiederti se sarai in grado di spiegarla domani, senza appoggiarti a scorciatoie o a frasi come “era la soluzione più semplice”.
Questo tipo di domanda non nasce dall’insicurezza, ma da responsabilità, perché implica la consapevolezza che il software non vive nel momento in cui viene consegnato, ma in tutto ciò che succede dopo.
Pensare in ottica headless significa accettare che alcune comodità si perdano in cambio di chiarezza.
Non puoi più nasconderti dietro comportamenti impliciti, perché ogni confine tra le parti del sistema deve essere tracciato intenzionalmente.
Questo rende il lavoro più esigente, ma anche più onesto, perché ogni decisione è visibile, discutibile e migliorabile.
Il cambio di mentalità riguarda anche il rapporto con gli strumenti.
Un CMS headless non è qualcosa che “ti fa lavorare meglio” in automatico, ma uno strumento che amplifica il modo in cui ragioni.
Se il tuo approccio è superficiale, amplificherà la confusione.
Se il tuo approccio è strutturato, amplificherà la solidità dell’architettura.
In questo senso, la tecnologia smette di essere una scorciatoia e diventa uno specchio.
C’è poi un aspetto identitario, che spesso viene ignorato.
Quando inizi a ragionare in termini di separazione delle responsabilità, contratti tra componenti e sostenibilità delle scelte, stai implicitamente spostando il tuo posizionamento professionale.
Non sei più solo quello che “fa andare le cose”, ma quello che può spiegare perché funzionano in un certo modo e perché continueranno a farlo anche quando il progetto crescerà.
Il CMS headless, alla fine, non è il punto di arrivo, ma un indicatore.
Indica che hai superato la fase in cui bastava far funzionare qualcosa e sei entrato in quella in cui conta poter difendere ogni scelta davanti a chi ha sufficiente esperienza per fare domande scomode.
Ed è proprio in quel momento che smetti di essere un assemblatore di soluzioni e inizi davvero a comportarti come un progettista del software.
Se leggendo questo articolo ti sei ritrovato più volte a pensare che il problema non fosse il CMS, ma il modo in cui sei stato abituato a ragionare finora, allora probabilmente sei già oltre la fase dei tutorial e delle soluzioni “che funzionano”.
A questo punto la differenza non la fa un nuovo strumento, ma un contesto che ti aiuti ad allenare davvero il pensiero architetturale, quello che rende le scelte spiegabili, difendibili e sostenibili nel tempo.
Il nostro Corso Architetto Software AI nasce esattamente per questo tipo di sviluppatore: chi non vuole imparare cosa usare, ma come pensare quando il software cresce e le decisioni iniziano a pesare.
Se questo approccio ti è familiare, vale la pena dare un’occhiata e capire se è il passo giusto per te, ora.
Lascia i tuoi dati nel form qui sotto