

A cosa serve persistere i dati della tua applicazione?
Per poterli mostrare all'utente! Vero, ma non è l’unica risposta, soprattutto se ti trovi davanti ad applicazioni con regole di business molto complesse.
Lascia che ti spieghi con un esempio.
Immagina il tuo prossimo viaggio: una spiaggia, relax, un cocktail e finalmente il tempo libero per poter leggere il tuo libro preferito. O magari sei una persona più avventurosa: zaino in spalla, lunghe camminate per raggiungere e scoprire luoghi incredibili.
Non vedi l’ora, dico bene?
Se hai vissuto anche solo una volta un viaggio simile, sai bene quanto lavoro richieda l’organizzazione e quante ore hai dovuto passare per i siti di viaggio o delle compagnie aeree.
Avrai notato come ogni volta che guardi un pacchetto viaggi o un volo, il prezzo è sempre differente. Peggio ancora nello stesso momento due persone o più persone che visualizzano lo stesso prodotto ricevono offerte differenti.
Il pricing dei prodotti su internet ha regole sempre più complesse basate su moltissimi fattori di cui spesso ignoriamo l’esistenza.
Pensaci. Ogni applicazione ha bisogno di salvare i dati che dovrà mostrare all’utente, oltre a persistere tutta una serie di dati che l’utente mai vedrà e che serviranno solo per poter eseguire le proprie logiche di business.
La situazione è ancora più complessa. Lo stesso dato è possibile che sia mostrato all’utente in forme, aggregazioni e modi molto differenti in base al caso d’uso in cui l’utente si trova di fronte.
Visto così è chiaro quanto sia difficile disegnare un unico modello dati che possa allo stesso tempo ottimizzare tutte queste differenti tipologie di accesso.
Per chi sviluppa software questo sembra il problema più complicato da affrontare.
Come facciamo quindi a progettare questo unico, ottimizzato modello dati?
La cruda risposta è semplice: non puoi.
Stai dicendo che sistemi complessi come Amazon, Airbnb o i sistemi di prenotazioni di biglietti aerei non hanno un unico modello dati?
Si dico esattamente questo.
Il “segreto” sta nell’eliminare una semplice parola: “unico”.
Hai due soluzioni: la prima è creare una architettura a microservizi. Infatti se crei piccoli servizi che interagiscono tra loro in modo distribuito ed isolato, potrai creare un modello dati specifico per ogni microservizio. Poiché ogni servizio si occupa solo di una minima parte delle funzionalità della applicazione, è probabile che il modello dati debba tenere conto di poche operazioni e può essere quindi più semplice, piccolo ed ottimizzato solo per esse.
Non tutti i sistemi però sono così grandi da avere la necessità di una architettura a microservizi, inoltre sviluppare un sistema distribuito aumenta la complessità di gestione e monitoraggio.
La seconda soluzione è CQRS.
Che cos’è CQRS?
CQRS sta per “Command Query Responsability Segregation” ed è una soluzione di modellazione del software il cui obbiettivo è di separare l’accesso dati in scrittura (command) da quello di lettura (query).
Questa separazione si basa sul principio che l’accesso in scrittura avviene in modo e con logiche differenti da quello in lettura, di conseguenza i relativi strati dati devono essere progettati in modo diviso e focalizzato secondo la propria funzione.
Per “separazione” si intende che dobbiamo costruire due database, uno per le letture ed uno per le scritture?
Non necessariamente, anche se è una pratica diffusa e molto utile in vari scenari. Te ne parlerò in modo approfondito in un altro articolo.
Ora ti voglio fare un esempio di uno scenario in cui è possibile prevedere due modelli differenti basato su un unico storage fisico.
Usare CQRS con un solo database
Immagina di avere una caso d’uso dove devi persistere in un database relazionale (Microsoft SqlServer ad esempio) una entità complessa come un ordine di un ecommerce, formata da tante sotto entità. Un ordine è composto da linee d’ordine, intestazione, dati di spedizione… Persistere questi dati in un database relazionale significa inserire in modo transazionale righe in più tabelle con relazioni uno-a-uno (intestazione dell'ordine) e uno-a-molti (linee d’ordine), correlate da chiavi esterne.
Il tuo caso d’uso richiede di accedere agli ordini in molti modi diversi e prelevare parti sempre differenti del grafo del tuo ordine: ti serve ad esempio, capire quali sono i prodotti più venduti, il totale degli ordini di un cliente, il valore medio degli ordini in una specifica città…
Ricapitolando: persistere un ordine ti richiede di gestire la scrittura di un grafo su un database relazionale, interrogare l’ordine ha come necessità eseguire query (molto) ottimizzate su una porzione di grafo.
Che tecnologia utilizzi per il tuo modello dati?
Come puoi notare, la scrittura e la lettura dell’ordine hanno problematiche tecniche da rispettare molto differenti tra loro. Mi spiego meglio.
Hai mai provato a scrivere le query sql che persistono un grafo complesso su un db relazionale? Spero di no, ma se tu ci avessi provato avresti notato quante query devi scrivere, come è noioso dover gestire la propagazione delle chiavi esterne quando generi chiavi auto-incrementali per identificare l’entità, come è facile dimenticarsi di aggiornare una query quando cambi un campo….
Di contro, le tante letture di porzioni di grafo ti richiedono di scrivere query ottimizzate che fanno largo uso di join, aggregazioni, filtri…
Ragioniamoci.
Se dovessi considerare più importanti le scritture, probabilmente ti affideresti ad un ORM (ad esempio Entity Framework) capace di gestirti il mapping di un database relazionale e persisterti un grafo complesso su più tabelle, con una sola istruzione. Tutto bello e tutto comodo, ma sai meglio di me come un ORM in lettura faccia del suo meglio ma a volte non genera le query più ottimizzate per interrogare il database: se prediligessi le letture saresti costretto a non usare un ORM ed scegliere di scrivere le query a mano oppure affidarti ad un tool come Dapper.
Fatte queste considerazioni, che tecnologia useresti per scriverti il tuo modello dati?
Detto in altri termini, rinunceresti alla comodità di un ORM per avere query ottimizzate?
Questo è un tipico caso in cui CQRS ti permette di non rinunciare a niente.
Infatti puoi definire un modello basato su un ORM come Entity Framework che utilizzerai per semplificarti la vita con le sole scritture sullo storage (Command o Write layer) ed un modello di lettura (Query layer) scritto con ADO.NET o Dapper, per accedere nel modo più performante possibile ai tuoi dati.
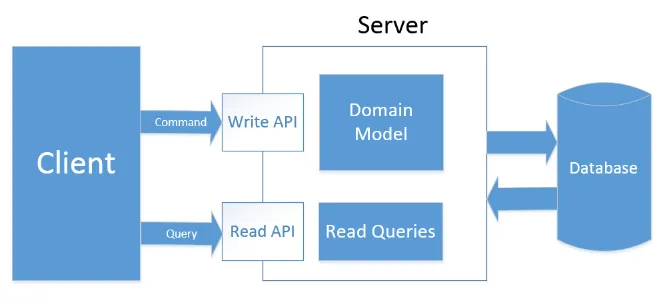
Lo so cosa stai pensando.
“Io uso un database non relazionale e non mi faccio tutti questi problemi”.
Vero, ma non sempre è possibile. A volte hai dei vincoli tecnologici che non puoi cambiare ed il database è il vincolo che più spesso ti trovi imposto.
Inoltre, esistono tantissime applicazioni che sono nate su database relazionali e non possono essere migrate su un database non relazionale.
Con alcuni grossi clienti ci siamo trovati in un contesto simile: applicazioni vecchie di 10 anni con Microsoft SqlServer, che usavano un ORM su cui ogni ottimizzazione possibile era stata fatta.
All’inizio tutto bene ma l’aumento delle funzionalità e degli utenti negli anni hanno fatto sì che le performance di accesso ai dati divenissero non più accettabili.
Come abbiamo rimodernizzato il sistema senza stravolgerlo?

Esattamente come ti ho illustrato poco fa: lo strato dati esistente basato su ORM è diventato il modello in scrittura e lo abbiamo affiancato con un modello dati di sola lettura con query scritte ad hoc con Dapper.
In questo modo abbiamo creato un nuovo strato pensato ed ottimizzato per rendere l’applicazione più responsiva possibile diminuendo i tempi di richiesta anche del 70%, il tutto senza stravolgere il codice, con un costo minore e con il cliente e l’utente felice.
Task based UI: CQRS come strumento di analisi
CQRS è nato all’interno del Domain Driven Design, un modello tattico e analitico per disegnare applicazioni che ha l’obbiettivo di eliminare le frizioni tra aspetti di business ed aspetti tecnici creando un vocabolario comune (Ubiquitous Language) e mantenendo sempre coerente il codice con i casi d’uso reali.
CQRS si rivela molto efficace in questo senso perché, attraverso i comandi, permette di disegnare le Task-Based UI.
Lascia che ti spieghi.
Generalmente le UI si sviluppano su logiche CRUD (create, read, update, delete). In breve: si divide il sistema in entità e si crea una maschera per ogni entità con i relativi metodi di creazione, interrogazione, update e cancellazione.
Questo tipo di UI, seppur semplici da sviluppare e con enormi vantaggi dal punto di vista della velocità di implementazione, hanno il problema che riflettono poco la vera operatività dell’utente facendo sì che chi usa l’applicazione abbia un senso di smarrimento.
Le task based ui risolvono esattamente questo problema: le interfacce sono sviluppate seguendo e raggruppando i processi e non le entità del sistema. Si studia ciò che deve fare l’utente, si suddividono le azioni in task operativi e si crea una maschera per ogni attività chiamato con il linguaggio usato dall’utente stesso.
Ti faccio un esempio: se devo modificare un indirizzo di un cliente, invece di andare sulla maschera di modifica del cliente e cambiare i soli dati dell’indirizzo, creerò una maschera di modifica del solo indirizzo.
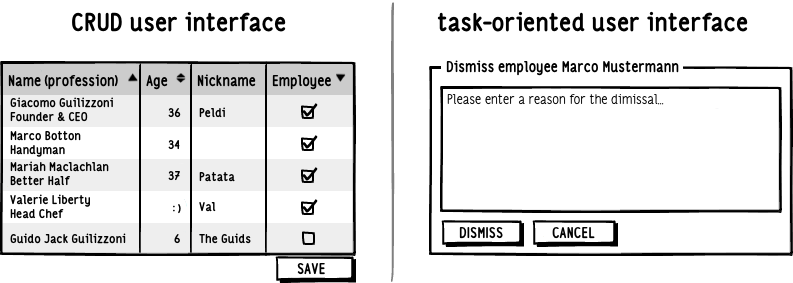
Questo approccio è più semplice perché:
- l’applicazione censisce con i task tutte le funzionalità che il business richiede
- l’utente non deve ragionare su come tradurre una attività in una o più operazioni sulla applicazione
- ogni task può essere semplicemente validato
- chi sviluppa la UI non deve conoscere le entità del sistema ma solo le funzionalità
Ma le task based UI, come si riflettono su CQRS?
Semplice: ogni task è una azione richiesta al nostro sistema. Richiedere una azione al nostro sistema si traduce nel mandargli un comando da processare.
Boom! Una maschera con un task per l’utente si traduce in codice nell’inviare un comando. Questo è esattamente ciò che esprime Domain Driven Design: diminuire la frizione tra business e codice ed usare un vocabolario comune. Questo approccio rende più produttivo l’utente che utilizza l’applicazione e più sereno lo sviluppatore che spenderà meno energie a tradurre i concetti di business in codice.
Ma non è finita qui.
Quando ti parlerò di Event Sourcing ti racconterò di un modello di analisi funzionale chiamata Event Sourcing che aiuta a studiare i processi di business.
CQRS e l’evoluzione dei sistemi
Hai sentito parlare di CQRS solo con event sourcing? È innegabile che CQRS con event sourcing stiano bene come il cacio sui maccheroni, ma sono due cose distinte. Per questo motivo ti parlerò di event sourcing abbinato a CQRS nel prossimo articolo.
È importante però che quando evolvi un sistema (soprattutto se esiste da molti anni), tu conosca e riesca a padroneggiare tutte le varianti in modo tale da scegliere la soluzione che ha il maggiore impatto in termini di risultato ma che risulti il meno invasivo possibile in termini di effort di sviluppo. Solo così riuscirai a contenere i costi, stupirti dei risultati positivi, ma soprattutto portare avanti senza impazzire la rimodernizzazione del tuo sistema di pari passo con lo sviluppo di nuove funzionalità.
È “facile” progettare un nuovo sistema con le tecniche all’avanguardia, il difficile è trovare il compromesso per evolvere al meglio le applicazioni che sostengono il tuo business da anni. A differenza di altri, noi non ti diciamo di riscrivere i tuoi sistemi ma ti affianchiamo in un percorso che ti metterà in grado di non buttare l’investimento fatto negli anni passati e farlo fruttare ancora negli anni a venire, così come abbiamo fatto con molte applicazioni legacy di multinazionali in vari settori.
Lascia i tuoi dati nel form qui sotto