

What is the purpose of persisting your application data?
To be able to show them to the user! True, but it is not the only answer, especially if you are faced with applications with very complex business rules.
Let me explain with an example.
Imagine your next trip: a beach, relaxation, a cocktail and finally free time to read your favorite book. Or maybe you are a more adventurous person: backpacking, long walks to reach and discover incredible places.
You can't wait, right?
If you have experienced a similar trip even just once, you know how much work the organization requires and how many hours you had to spend on travel or airline sites.
You may have noticed how every time you look at a travel package or a flight, the price is always different. Worse still, at the same time two people or more people viewing the same product receive different offers.
The pricing of products on the internet has increasingly complex rules based on many factors whose existence we often ignore.
Think about it. Each application needs to save the data that it will have to show to the user, as well as persisting a whole series of data that the user will never see and which will only be used to execute its business logic.
The situation is even more complex. The same data may be shown to the user in very different forms, aggregations and ways based on the use case the user is faced with.
Seen in this way, it is clear how difficult it is to design a single data model that can optimize all these different types of access at the same time.
For software developers this seems like the most complicated problem to deal with.
So how do we design this unique, optimized data model?
The stark answer is simple: you can't.
Are you saying that complex systems like Amazon, Airbnb, or airline ticket reservation systems don't have a single data model?
Yes, I say exactly this.
The “secret” lies in eliminating a simple word: “unique”.
You have two solutions: the first is to create one microservices architecture. In fact, if you create small services that interact with each other in a distributed and isolated way, you will be able to create a specific data model for each microservice. Since each service deals with only a small part of the application's functionality, it is likely that the data model needs to take into account few operations and can therefore be simpler, smaller and optimized only for them.
However, not all systems are so large that they require a microservice architecture, and developing a distributed system increases the complexity of management and monitoring.
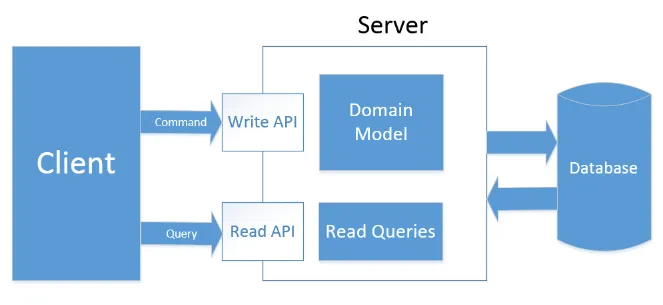
The second solution is CQRS.
What is CQRS?
CQRS stands for “Command Query Responsibility Segregation” and is a software modeling solution whose goal is to separate data access for writing (command) from data access for reading (query).
This separation is based on the principle that writing access occurs in a different way and with different logic than reading access, consequently the relevant data layers must be designed in a divided and focused way according to their function.
By “separation” do we mean that we have to build two databases, one for reads and one for writes?
Not necessarily, although it is a widespread and very useful practice in various scenarios. I will tell you about it in depth in another article.
Now I want to give you an example of a scenario in which it is possible to envisage two different models based on a single physical storage.
Use CQRS with a single database
Imagine having a use case where you have to persist in a relational database (Microsoft SqlServer for example) a complex entity such as an e-commerce order, made up of many sub-entities. An order is composed of order lines, header, shipping data… Persisting this data in a relational database means transactionally inserting rows into multiple tables with one-to-one (order header) and one-to-many (order lines) relationships, related by foreign keys.
Your use case requires accessing orders in many different ways and picking up different parts of your order graph: for example, you need to understand which are the best-selling products, the total orders of a customer, the average value of orders in a specific city...
In summary: persisting an order requires you to manage the writing of a graph on a relational database, querying the order requires executing (very) optimized queries on a portion of the graph.
What technology do you use for your data model?
As you can see, writing and reading the order have very different technical problems to be respected. Let me explain better.
Have you ever tried to write sql queries that persist a complex graph on a relational db? I hope not, but if you had tried you would have noticed how many queries you have to write, how tedious it is to manage foreign key propagation when generating auto-incremental keys to identify the entity, how easy it is to forget to update a query when you change a field...
On the other hand, the many readings of portions of the graph require you to write optimized queries that make extensive use of joins, aggregations, filters...
Let's think about it.
If you were to consider writing more important, you would probably rely on an ORM (for example Entity Framework) capable of managing the mapping of a relational database and persisting a complex graph across multiple tables, with a single instruction. All beautiful and all convenient, but you know better than me how a reading ORM does its best but sometimes does not generate the most optimized queries to query the database: if you preferred reading you would be forced not to use an ORM and choose to write the queries by hand or rely on a tool like Dapper.
Given these considerations, what technology would you use to write your data model?
Put another way, would you give up the convenience of an ORM for optimized queries?
This is a typical case where CQRS allows you not to give up anything.
In fact, you can define a model based on an ORM such as Entity Framework which you will use to simplify your life with only writing to the storage (Command or Write layer) and a reading model (Query layer) written with ADO.NET or Dapper, to access your data in the best possible way.
I know what you're thinking.
“I use a non-relational database and I don't have all these problems”.
True, but it's not always possible. Sometimes you have technological constraints that you cannot change and the database is the constraint that you most often find imposed on you.
Furthermore, there are many applications that were born on relational databases and cannot be migrated to a non-relational database.
With some large customers we found ourselves in a similar context: 10 year old applications with Microsoft SqlServer, which used an ORM on which every possible optimization had been done.
At the beginning everything was fine but the increase in functionality and users over the years meant that data access performance became no longer acceptable.
How have we modernized the system without upsetting it?

Exactly as I explained to you a moment ago: the existing ORM-based data layer became the write model and we supported it with a read-only data model with queries written ad hoc with Dapper.
In this way we have created a new layer designed and optimized to make the application as responsive as possible, reducing request times by up to 70%, all without distorting the code, with a lower cost and with a happy customer and user.
Task based UI: CQRS as an analysis tool
CQRS was born within the Domain Driven Design, a tactical and analytical model for designing applications that aims to eliminate friction between business aspects and technical aspects by creating a common vocabulary (Ubiquitous Language) and always keeping the code consistent with real use cases.
CQRS proves to be very effective in this sense because, through commands, it allows you to design Task-Based UIs.
Let me explain.
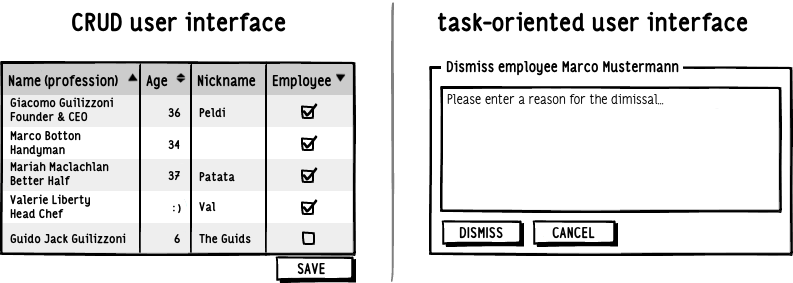
Generally, UIs are developed on CRUD (create, read, update, delete) logic. In short: the system is divided into entities and a mask is created for each entity with the related creation, query, update and deletion methods.
This type of UI, although simple to develop and with enormous advantages in terms of speed of implementation, has the problem that it poorly reflects the user's true operations, causing those who use the application to have a sense of bewilderment.
Task based UIs solve exactly this problem: the interfaces are developed by following and grouping the processes and not the entities of the system. We study what the user must do, divide the actions into operational tasks and create a mask for each activity called with the language used by the user himself.
I'll give you an example: if I need to modify a customer's address, instead of going to the customer's modification form and changing only the address data, I will create a form for modifying the address only.
This approach is simpler because:
- the application lists all the functions that the business requires with tasks
- the user does not have to think about how to translate an activity into one or more operations on the application
- each task can simply be validated
- whoever develops the UI does not have to know the entities of the system but only the functionalities
But how are task based UIs reflected in CQRS?
Simple: each task is an action requested from our system. Requesting an action from our system translates into sending it a command to process.
Boom! A form with a task for the user translates into code in sending a command. This is exactly what Domain Driven Design expresses: decreasing the friction between business and code and using a common vocabulary. This approach makes the user who uses the application more productive and the developer more relaxed, who will spend less energy translating business concepts into code.
But it didn't end here.
When I talk to you about Event Sourcing I will tell you about a functional analysis model called Event Sourcing that helps study business processes.
CQRS and the evolution of systems
Have you heard of CQRS with event sourcing only? It is undeniable that CQRS with event sourcing are as good as cheese on macaroni, but they are two distinct things. For this reason I will tell you about event sourcing combined with CQRS in the next article.
It is important, however, that when you evolve a system (especially if it has existed for many years), you know and are able to master all the variations in such a way as to choose the solution that has the greatest impact in terms of results but which is the least invasive possible in terms of development effort. Only in this way will you be able to contain costs, be amazed by the positive results, but above all carry on without going crazy with the modernization of your system in step with the development of new functions.
It is "easy" to design a new system with cutting-edge techniques, the difficult thing is to find the compromise to best evolve the applications that have supported your business for years. Unlike others, we don't tell you to rewrite your systems but we support you on a path that will enable you not to throw away the investment made in past years and make it pay off again in the years to come, as we have done with many legacy applications of multinationals in various sectors.
Leave your details in the form below